










この記事の内容
BigQueryから抽出したParquet形式のデータをPandas DataFrameとして読み込み、各行の数値に計算処理を行う必要があった。
現時点におけるレコードは数百万行であるものの、将来的に数千万レコードに増加することが想定されるため、コードをマルチプロセス対応しておき実行環境のCPUコア数に応じタスクを並列実行できるようにしたときに処理が高速化されずはずのキャッシュまわりで落とし穴があったときの話。
実行結果
| 実行時間(秒) | |
|---|---|
| 共有dictあり | 280 |
| なし(使い捨てローカルキャッシュ) | 7 |
Manager経由で得られるメインプロセス上の共有dictをサブプロセス間でキャッシュとして共有利用した結果、40倍も遅くなってしまった。
環境
MacBook Air上で実行した。
- macOS Ventura
- M2 8コア
- 16GBメモリ
アーキテクチャー
-
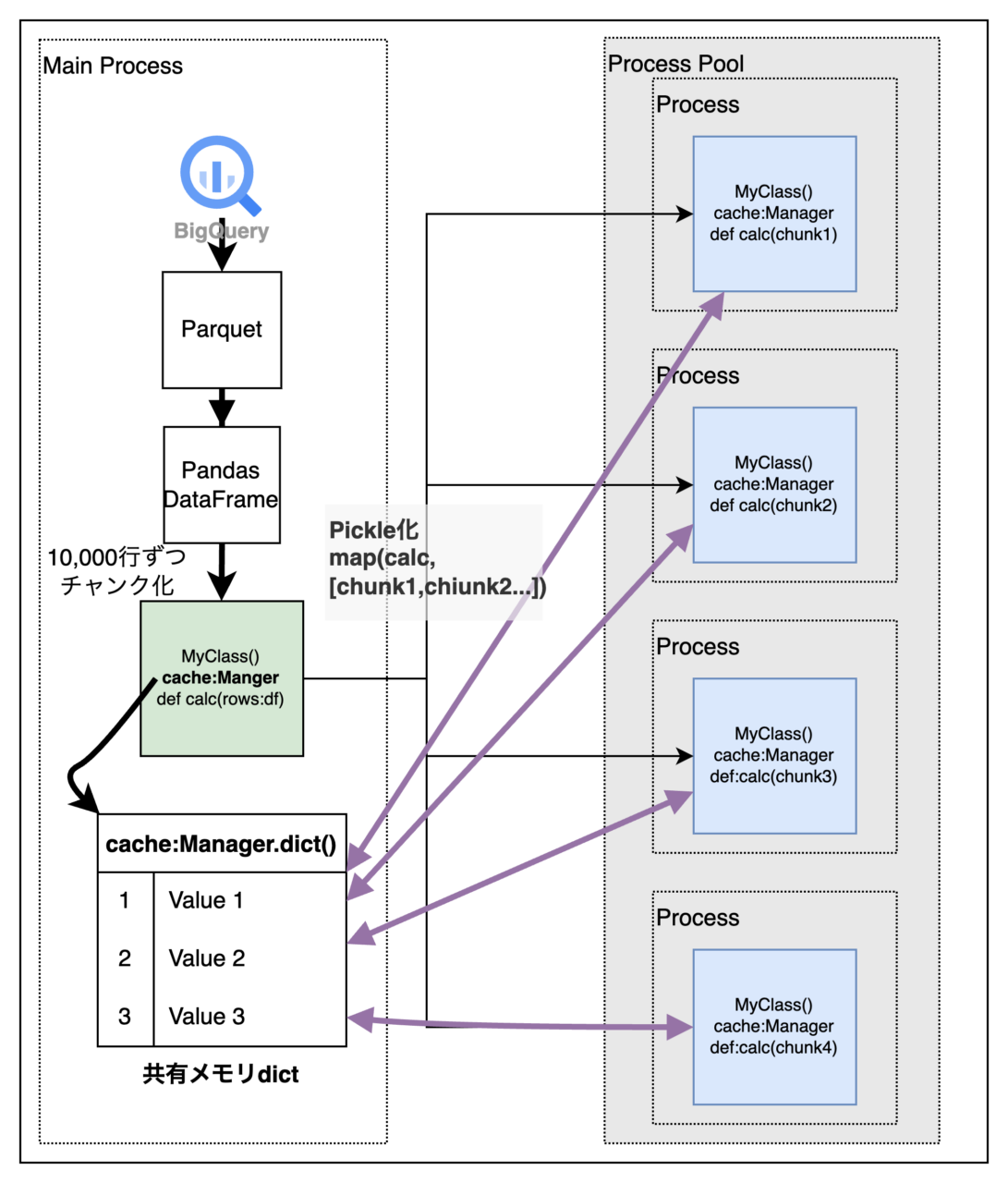
CPUコア数に応じた数のサブプロセスを起動し、MyClassのcalc関数を並列実行する
-
メインプロセス上の共有メモリdictをキャッシュとして利用する
-
サブプロセスは処理対象データを10,000件ずつPandas DataFrameとして受け取る
-
メインプロセス上のキャッシュはプロセスプールへのmap()で
プロキシとしてサブプロセスに渡り、すべてのサブプロセスからアクセスできる -
各サブプロセスの計算結果はメインプロセスの共有dictへキャッシュとして格納する
-
各サブプロセスではDataFrameを1行ずつiterateし、
キャッシュに同じ組み合わせがなければ計算を行う(キャッシュミス)
-
計算結果は元データのTimeStampとともにBigQueryに保存
原因
共有メモリdictへのアクセスはdictへのアクセスと比べるとかなり遅い。stackoverflowにも共有dictは117倍遅いという同様のコメントがあった。
キャッシュ対象の演算処理別がリモートAPIに依存するなどして数百マイクロ~数ミリセカンドオーダーの実行時間にならない限りは共有メモリdictがオーバーヘッドとなり処理時間を増やしてしまうようだ。(今回は共有dictのアクセス時間をプロファイラで測定したわけではないためあくまでもイメージ。)
改善策
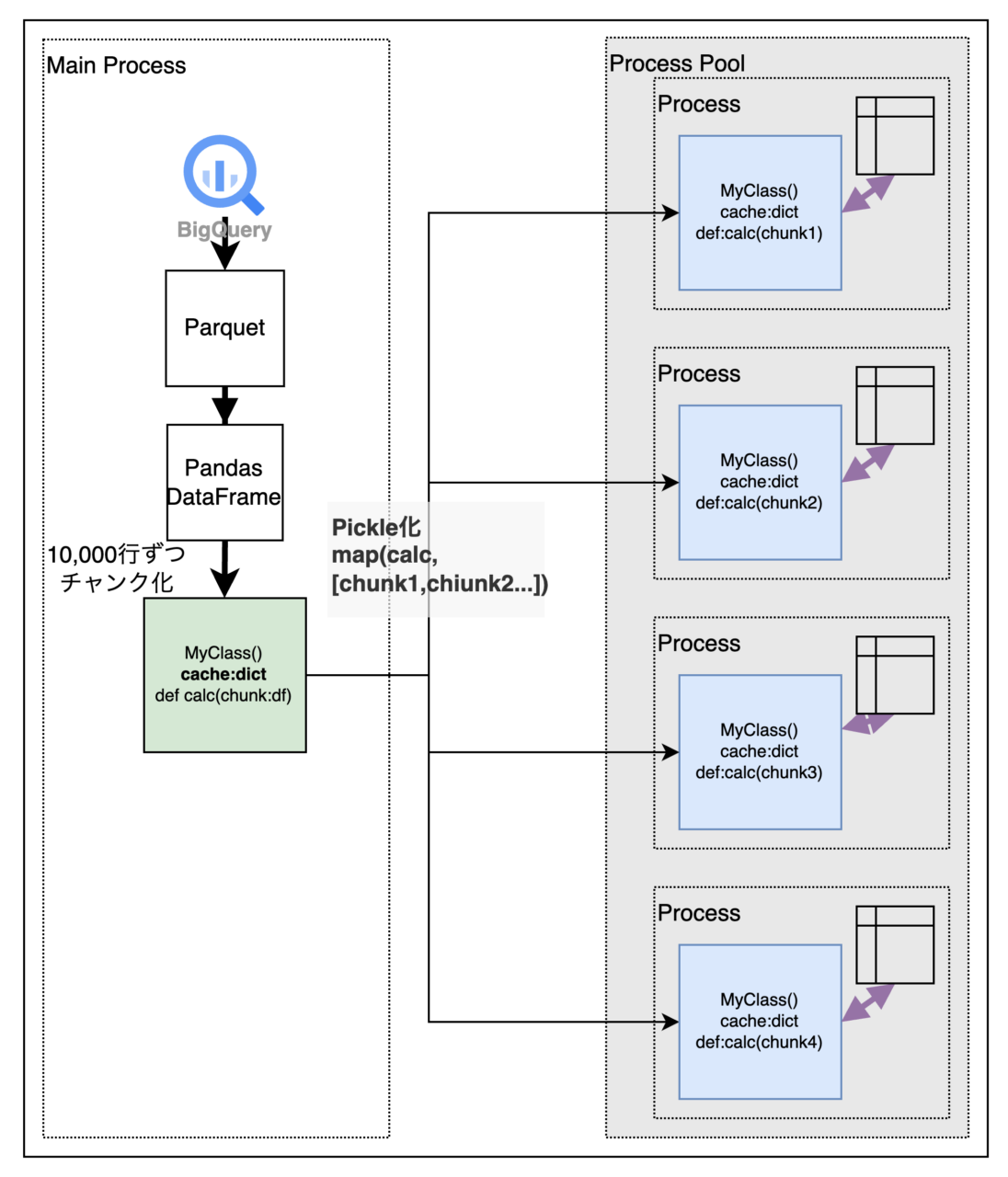
メインプロセスに共有dictを持たせるのをやめ、各サブプロセスに使い捨てのローカルのキャッシュdictを持たせる単純な実装とした。新しいサブプロセスが生成されるとキャッシュ再構築が必要なデメリットはあるがこのケースだと共有dictアクセスタイムに影響し発生する待機時間のオーバーヘッドを回避できる。
あとがき
multiprocessing.shared_memoryを使ってサブプロセス間で同一のメモリ空間にアクセスさせるという方法もあるがdict型は使えないようだ。
マルチプロセス化するタスクの処理時間が長くなるタイミングでPythonで高速にキャッシュを共有する方法を再検討する。

